用蓝印RPA遍历网页中的相似元素并抓取内容
2023-12-24 23:06:36 395
用RPA采集数据时,需要经常对多个相似元素的内容进行采集。这里教大家如何用蓝印RPA实现遍历网页中的相似元素并采集相关内容。
这里以采集百度首页上的热搜标签为例:
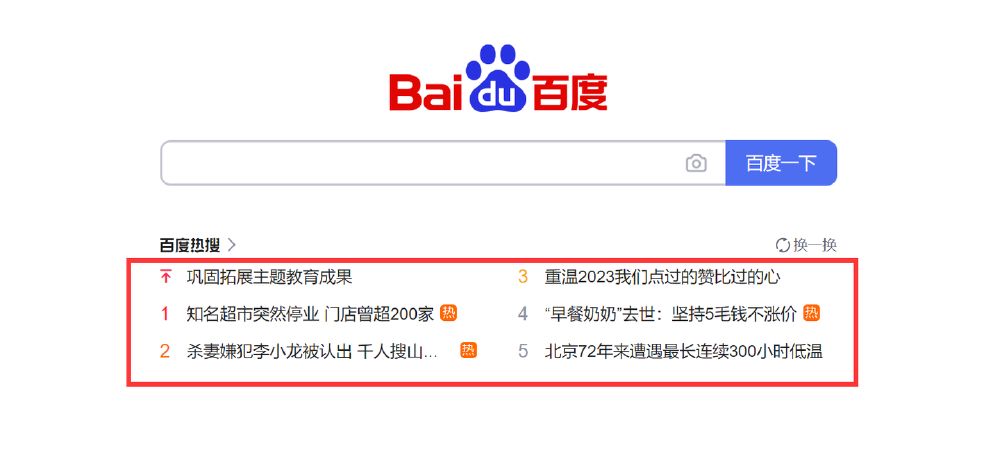
添加图片注释,不超过 140 字(可选)
流程逻辑:1、访问百度首页->2、生成热搜标签页的xpath路径->3、获取相似元素个数->4、通过For循环来遍历每个元素->5、在for循环流程里获取标签页的文字内容
流程步骤如下:
1、添加加载url流程,填入要采集内容的网址

添加图片注释,不超过 140 字(可选)
2、获取相似元素个数
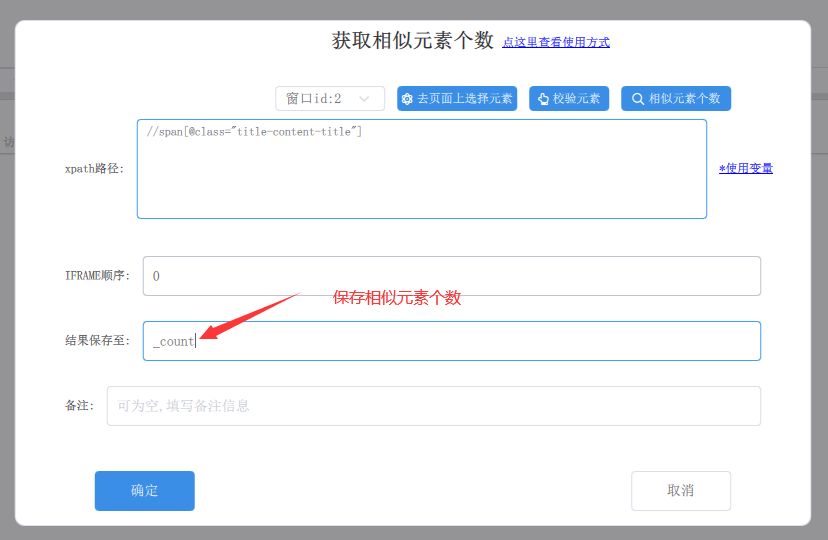
添加图片注释,不超过 140 字(可选)
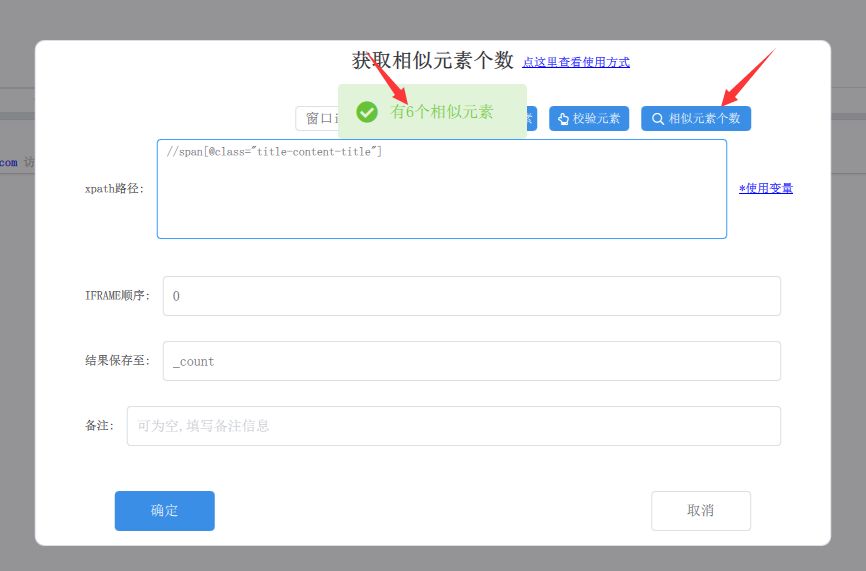
添加图片注释,不超过 140 字(可选)
3、通过for循环来遍历各个标签页
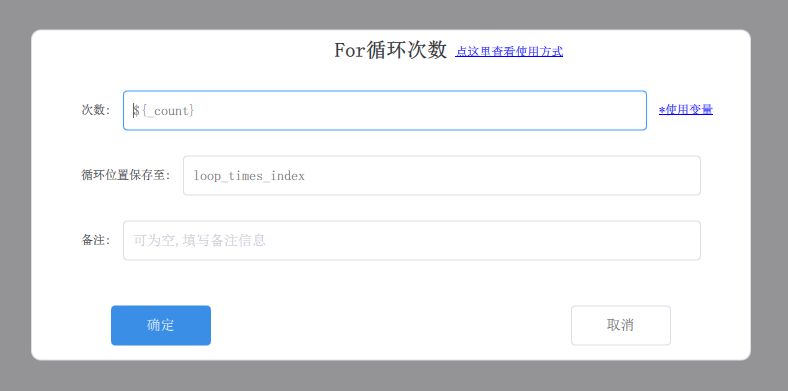
添加图片注释,不超过 140 字(可选)
4、在for循环流程里获取当前热搜标签的内容,这里使用“通过xpath获取属性值”的流程步骤来获取innerText的内容
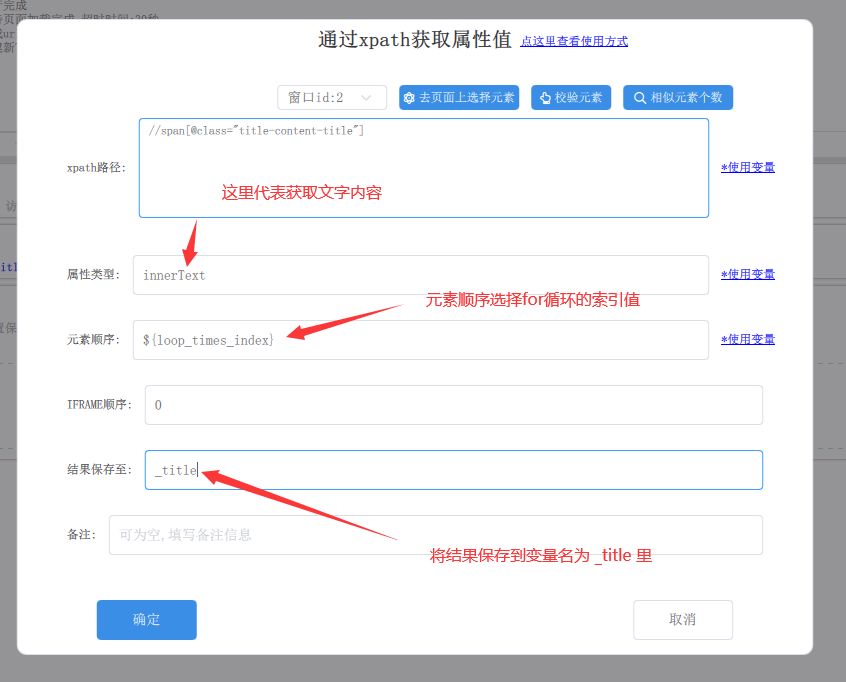
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
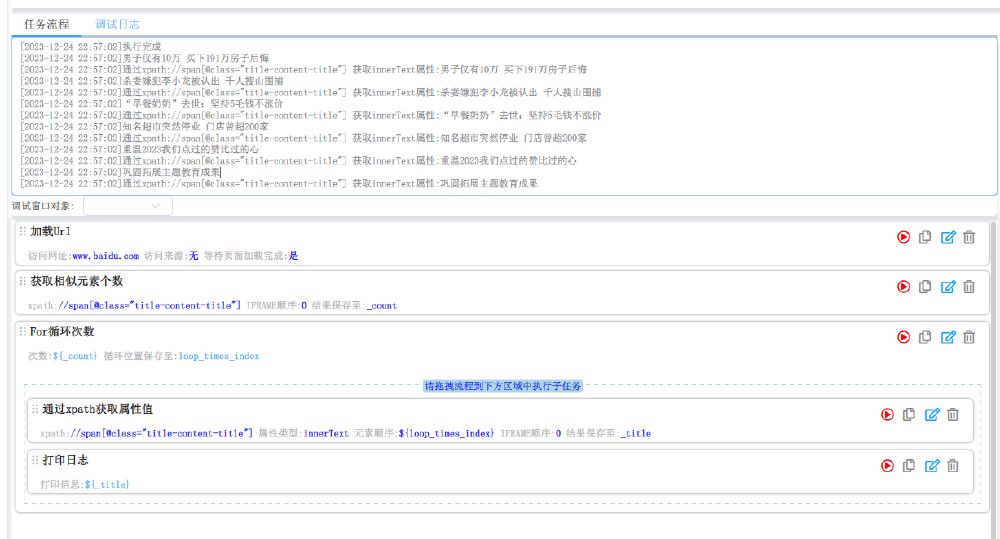
设置完流程后点击运行,数据就采集到啦,这里我们只对标题进行日志输出打印。从上面的窗口上我们可以看到内容已经都采集到了。蓝印RPA使用简单,仅仅3个流程就能实现对多个相似的元素进行内容采集。